顔文字の辞書を充実させるため、ネット上で配信されている辞書を活用できないものか。 そう考えて以前awkで変換する方法を実施していましたが、エスケープしなければいけない文字の扱いが考慮できていませんでした。
よくよく考えると「はてなキーワードからSKK辞書を作る」スクリプトにはその処理が入っているはずだからちょっと改造すればうまくいくはず…ということで試してみたら、うまくいったのでやりかたをまとめます。
前提
- skkdic-expr2 が使えること
- rubyがインストールされていること
が前提です。
スクリプトと使い方
googleime2skk.rb
require 'nkf' class String # borrowed from http://openlab.jp/skk/skk/tools/filters/skkdictools.rb def concatify #if !(/^([-\w]+.*)$/ =~ self) && (/[;\r\n\/\"]/ =~ self) # []の処理をしないとskkdic-expr2がSEGVる。 # see http://d.hatena.ne.jp/rubikitch/20091022/1256186001 if /[\[\];\r\n\/\"]/ =~ self tmp = self.gsub(/;/, '\\\073').gsub(/\//, '\\\057').gsub(/\r/, '\\r').gsub(/\n/, '\\n').gsub(/"/, '\\"').gsub(/[\[\]]/, '') return '(concat "' + tmp + '")' else return self end end end ARGF.each do |line| line.chomp! furigana, keyword, shubetsu = line.split(/\t/, 3) if furigana.empty? next # ふりがながないキーワードを無視 end if furigana == keyword next # ひらがなだけのキーワードを無視 end if furigana == NKF.nkf('-Ee -m0 --hiragana', keyword) next # カタカナ語は無視 end puts "#{furigana} /#{keyword.gsub(/&/, '&').concatify}/" end
使い方
$ ruby googleime2skk.rb google_std.txt |nkf -e -x > tmp.skkdic $ skkdic-expr2 -o SKK-JISYO.google tmp.skkdic
google_std.txt がグーグル日本語入力の辞書です。 MS-IMEもATOKも辞書の形式がだいたい同じなので、使えるのではないかと思います。
nkfをかませて文字コード変換しているのは、Google日本語入力の辞書はUnicodeなので、SKK辞書のEUCに文字コードを変換するためです。 顔文字辞書などで半角カナをそのまま活用するため -x をつけています。
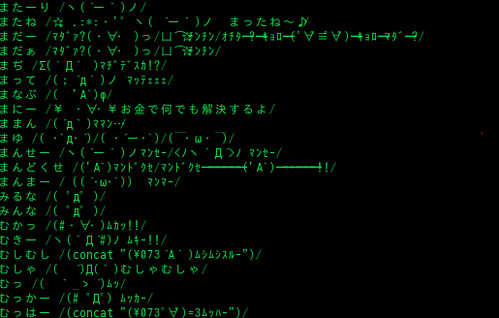
充実のSKKライフを!